

"Wie ein Datensatz von 7.000 Artikeln und 300.000 Kommentaren uns mehr über die Schweiz verrät, als wir vielleicht wissen wollen"
von Andreas Büchler
Die Idee
Kennen Sie die Geschichte jenes aufgebrachten Vaters, der in einen Target-Supermarkt stürmte und forderte zu wissen, warum seiner minderjährigen Tochter Babyproduktwerbung zugeschickt wurde? Wochen später entschuldigte er sich kleinlaut – Target wusste durch clevere Datenanalyse vor ihm selbst, dass seine Tochter schwanger war.
Diese Anekdote brachte mich auf eine Idee: Was könnten öffentlich zugängliche Daten von 20 Minuten über die Schweizer Gesellschaft verraten? Wer kommentiert was, wann und warum? Welche Themen erzeugen welche Reaktionen? Und würde ich womöglich ähnlich überraschende Einsichten gewinnen können?
Für die übliche Datenanalyse hätte ich einfach einen bestehenden Datensatz nehmen können. Aber warum den einfachen Weg wählen, wenn es auch kompliziert geht? Im Rahmen meiner Weiterbildung wollte ich etwas wirklich Spannendes schaffen – und so begann mein dreimonatiges Date mit 20 Minuten.
Der technische Teil
Den Crawler aufsetzten
Um an die Datenschätze von 20 Minuten zu gelangen, programmierte ich einen Scraper in Python. Dieses Skript besuchte jeden Abend um 22 Uhr die Webseite und sammelte systematisch alles ein, was er finden konnte:
def scrape_articles():
driver = setup_driver()
subcategory_urls = get_subcategory_urls(driver)
article_urls = get_article_urls(driver, subcategory_urls)Mein kleiner Freund war äusserst gründlich. Er navigierte durch die verschiedenen Kategorien, öffnete Artikel, extrahierte deren Inhalt und tauchte sogar in die Kommentarsektionen ein, um die Reaktionen der Leser zu erfassen:
def extract_article_data(driver, article_id, target_date_str):
data = {'article_id': article_id}
data['scraping_date'] = datetime.today().strftime('%Y-%m-%d')Die grösste technische Herausforderung? Die Kommentare – beim Scrollen lädt 20 Minuten dynamisch weitere Kommentare nach. Meine Lösung:
while True:
last_height = driver.execute_script("return document.body.scrollHeight")
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
breakNach drei Monaten täglichen Scrapens hatte ich den Jackpot: über 7.000 Artikel und sage und schreibe 300.000 Kommentare. Ein wahrer Datenschatz:
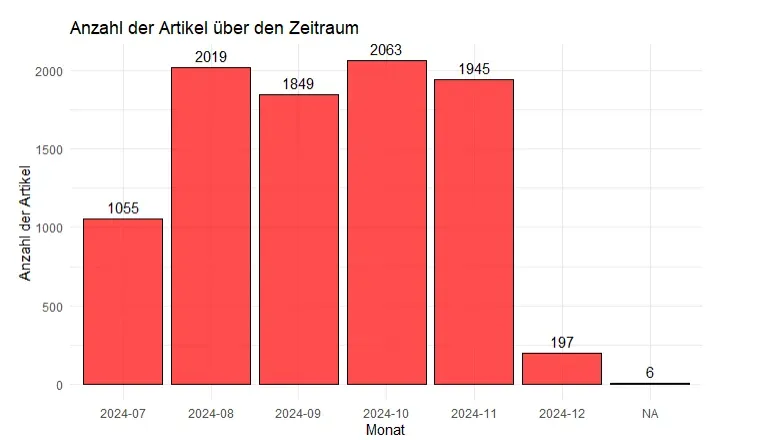
In der Spitze wurden über 2.000 Artikel pro Monat gesammelt, mit insgesamt:
- Über 9.000 Artikel von Juli bis Dezember 2024
- Über 384.000 Kommentare im gleichen Zeitraum
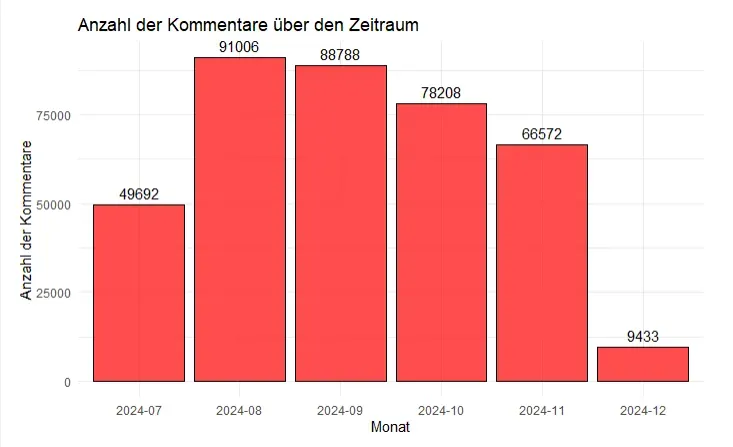
Besonders der August und September 2024 waren Spitzenmonate mit über 90.000 Kommentaren. Die Leser waren offensichtlich in Mitteilungslaune!
Die Analyse
Mit meinen gesammelten Daten, wechselte ich zu R für die Analyse:
# Artikel Daten einlesen
articles_1 <- read_excel("D:/ATBN/20min_Daten/com_data/Artikeldaten.xlsx")
# Comments Daten einlesen
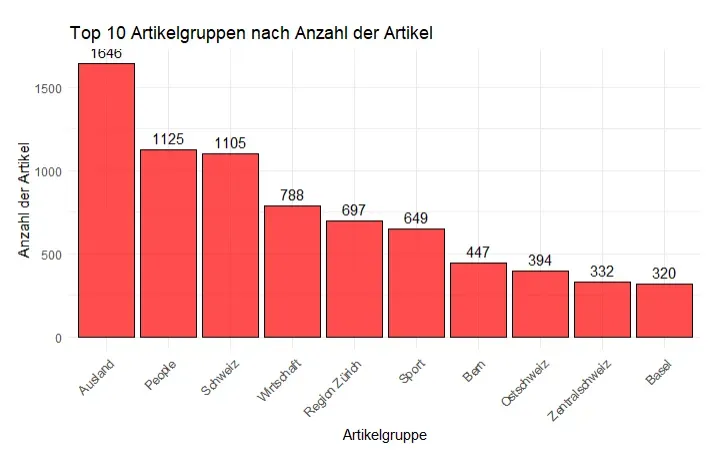
comments_1 <- read_excel("D:/ATBN/20min_Daten/com_data/Kommentardaten.xlsx")Die meisten Artikel wurden in den Kategorien Ausland (1.646), People (1.125) und Schweiz (1.105) veröffentlicht.
Neben einfachen deskriptiven Statistiken nutzte ich:
- Sentiment-Analyse, um die emotionale Färbung der Kommentare zu erfassen
- Netzwerkanalyse, um Verbindungen zwischen Autoren und Themen zu visualisieren
- Lineare Regression, um Zusammenhänge zwischen Artikelzahlen und Kommentaraufkommen zu untersuchen
- Textmining und Wortwolken, um häufige Begriffe in Kommentaren zu identifizieren
Was die Daten verraten
Die Kommentarfreudigen
Die Analyse zeigte deutlich: Nicht alle Themen sind gleich kommentarwürdig. Die Top-10-Kategorien mit den meisten Kommentaren waren eine folgende:
| Kategorie | Anzahl Kommentare | Anzahl Artikel | Durchschnitt |
|---|---|---|---|
| Abstimmungen | 2814 | 14 | 255.82 |
| Schweiz, Abstimmungen | 2114 | 15 | 176.17 |
| Schweiz | 11461 | 511 | 69.05 |
| Biden-Rückzug | 3417 | 27 | 155.32 |
| Wirtschaft | 8696 | 878 | 128.84 |
| Ausland, US-Wahlen | 1607 | 22 | 124.57 |
| Trump-Attentat | 539 | 15 | 107.80 |
| Ukraine | 553 | 193 | 106.37 |
| Krankenkassen | 297 | 3 | 99.00 |
| Community | 1311 | 322 | 91.06 |
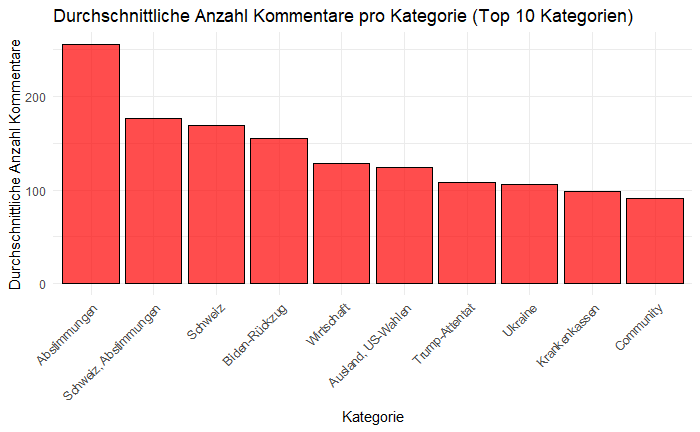
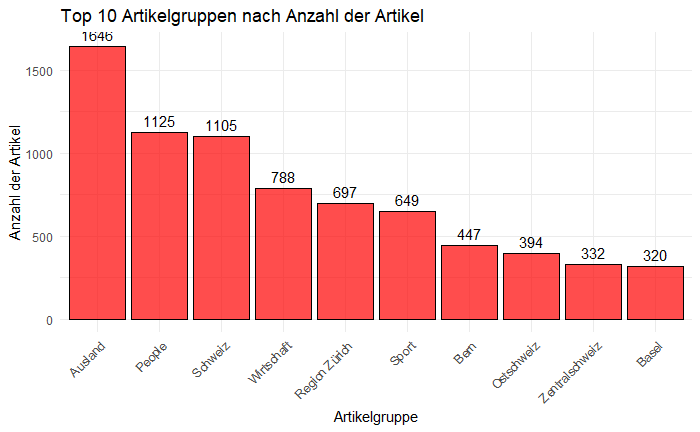
Da sage noch jemand, die Schweizer interessierten sich nicht für Politik! Die Daten erzählen eine andere Geschichte: Während Katzenvideos und Promi-News sicher geklickt werden, sind es politische Themen, die zum Kommentieren anregen.
Aber an der Artikel Anzahl sind wohl andere Themen besser geklickt oder haben einfach mehr Themen.
Mit einer statistischen Analyse konnte ich sogar 95%-Konfidenzintervalle für die Kommentarzahlen berechnen. Für Abstimmungen liegt der wahre Durchschnittswert mit 95%iger Wahrscheinlichkeit zwischen 211 und 301 Kommentaren pro Artikel.
Die Gefühlswelt der Kommentarspalte
Die Sentiment-Analyse der Kommentare ergab ein erwartetes Bild:
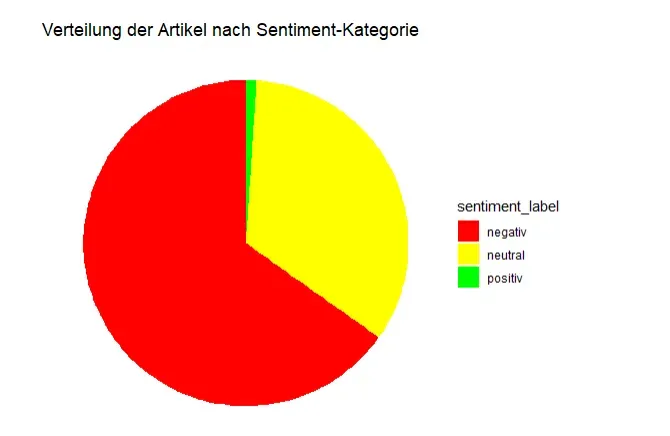
- Über 60% der Artikel erzeugten überwiegend negative Kommentare (rot)
- Etwa 35% neutrales Feedback (gelb)
- Nur ein winziger Bruchteil von unter 5% überwiegend positive Reaktionen (grün)
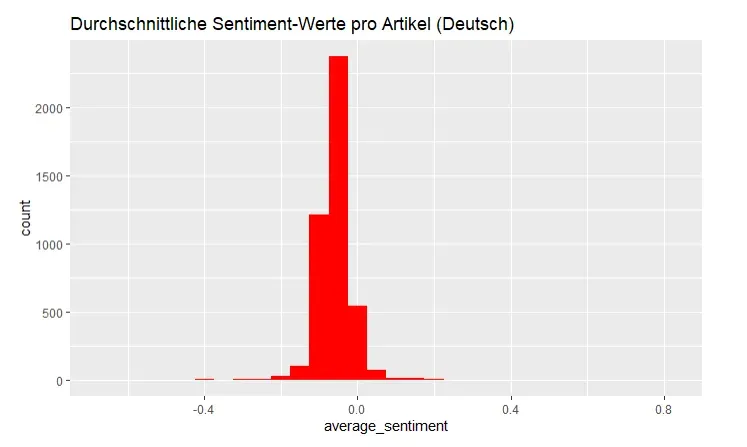
Die statistische Verteilung der Sentiment-Werte zeigt dabei eine deutliche Neigung ins Negative:
Besonders aufschlussreich war die zeitliche Entwicklung des Sentiments:
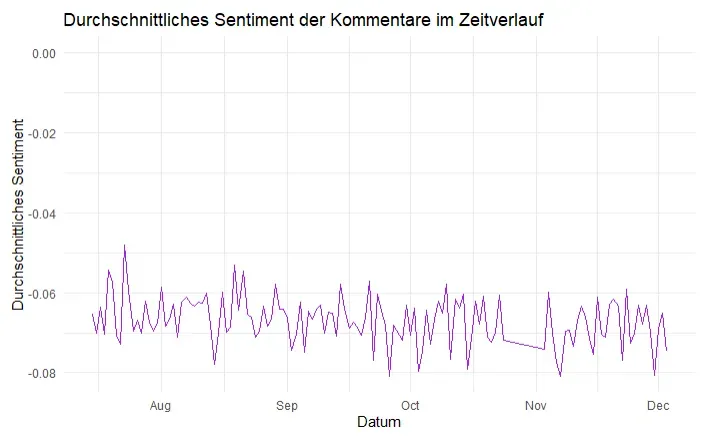
Die Kurve zeigt ein durchgängig negatives Sentiment mit Werten zwischen -0.05 und -0.08, mit gelegentlichen kleinen Erholungen. Interessanterweise sind keine klaren positiven Ausschläge zu sehen – die Schweizer Kommentarspalte bleibt konsequent kritisch.
Die digitale DNA der Schweizer Kommentarspalte
Besonders spannend sind die Wortwolken der meistgenannten Begriffe in verschiedenen Themenkategorien. Diese Wortwolken offenbaren faszinierende Einblicke:
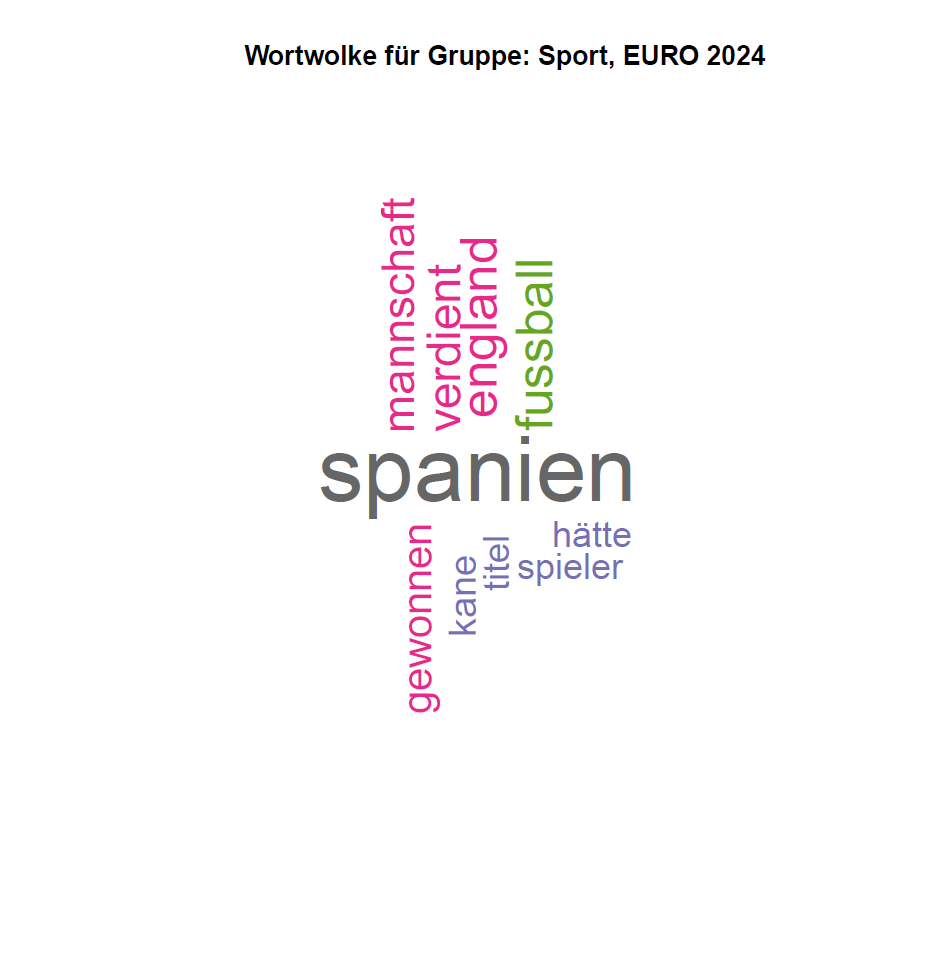
EURO 2024 Wortwolke
Bei Sport/EURO 2024 dominiert "Spanien" als Europameister, gefolgt von "Mannschaft", "verdient" und "gewonnen". Die Schweiz wahr wohl sehr einverstanden mit dem Europameister.

Region Zürich Wortwolke
Region Zürich wird stark mit dem öffentlichen Verkehr assoziiert: "SBB", "Ticket", "Kontrolleur" und "Busse" sind häufig. Die Menschen in Zürich haben wohl häufig negative Erfahrungen im öffentlichen Verkehr.

Wirtschaft Wortwolke
Wirtschaft-Kommentare drehen sich auffällig oft um "Schuhe", "Swatch", "Minuten" und "Federer" - offenbar beliebte Konsumthemen. Könnte sein das es einige Artikel über die Firma On gab.

Trump-Attentat Wortwolke
Bei Trump-Attentat-Artikeln dominieren erwartungsgemäss "Trump", "USA" und "Amerika", aber auch "Wahl" und überraschenderweise "gut".
Was auch spannend ist. Jeder kennt das Sprichwort "Sag niemals nie". Es braucht aber bald wohl auch eins mit immer. Denn das schreiben wir ganz schön oft:

Die emotionalen Reaktionen
Eine Analyse der häufigsten Reaktionen auf die Kommentare nach Sentiment-Kategorie zeigt interessante Muster:
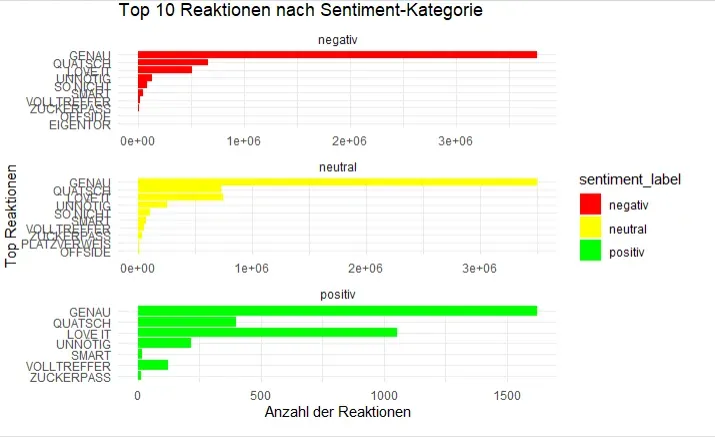
"GENAU" ist die mit Abstand beliebteste Reaktion in allen Sentiment-Kategorien - ob negativ, neutral oder positiv. Das spricht für eine starke Bestätigungstendenz bei der Reaktion auf Kommentare. Also alle bleiben in der Bubble wo Sie möglich gleicher Meinung sind.
Verteilung der Kommentare
Der grosse Teil der Artikel erhält eher wenige Kommentare, während einige wenige Artikel regelrechte Kommentarschlachten auslösen:
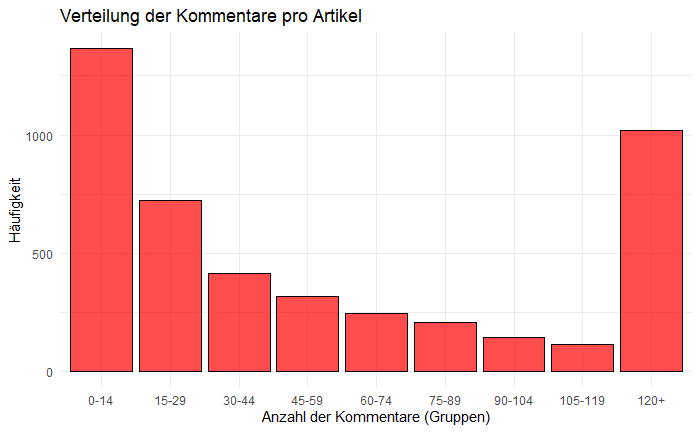
Die meisten Artikel fallen in die Kategorie mit 0-14 Kommentaren, aber eine signifikante Anzahl erreicht auch über 120 Kommentare. Eine klassische "Long Tail"-Verteilung, die typisch für Online-Engagement ist.
Korrelationen und Kausalitäten
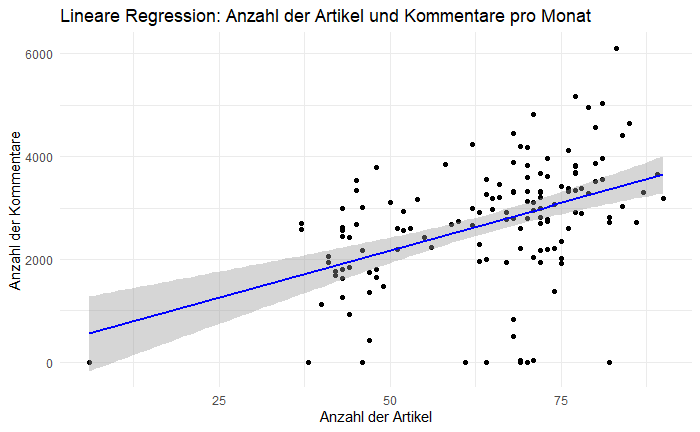
Die lineare Regression zeigte einen klaren Zusammenhang: Mehr Artikel führen zu mehr Kommentaren, allerdings mit einem wichtigen Vorbehalt – die Themenkategorie ist entscheidend. Ein einzelner Abstimmungsartikel generiert durchschnittlich mehr Kommentare als fünf Artikel über Prominente.
Der Weg ist das Ziel
Dieses Projekt war mehr als nur eine technische Übung für meine Weiterbildung. Es war ein Beweis dafür, dass echte Erkenntnisse oft aus der Kombination verschiedener Fähigkeiten entstehen:
- Technisches Know-how (Python für das Scraping, R für die Analyse)
- Statistisches Verständnis (von einfachen Visualisierungen bis zu Regressionsmodellen)
- Journalistische Neugier (die richtigen Fragen an die Daten stellen)
Statt einen fertigen Datensatz zu nehmen, habe ich den Weg der zusätzlichen Meile gewählt – vom Aufbau des Scrapers über die Datenbereinigung bis zur Analyse. Das Ergebnis war nicht nur ein erfolgreicher Abschluss meiner Weiterbildung, sondern auch ein faszinierender Einblick in die digitale Schweizer Gesellschaft. Welcher für mich noch nicht beendet ist. Deshalb gebe ich die Daten frei. Wichtig zu sagen der Datensatz ist nicht perfekt aber hat spannende Daten:
Schreib mir gerne wenn Ihr Ideen mit dem Datensatz habt eine Mail: